> ## Documentation Index
> Fetch the complete documentation index at: https://docs.decepticon.red/llms.txt
> Use this file to discover all available pages before exploring further.
# History & Evolution
> The architectural journey of Decepticon: from Purple Team AI to Autonomous Hacking.
The development of Decepticon did not start overnight. It is the culmination of years of research into applying artificial intelligence to offensive security. Understanding our past approaches provides context for why Decepticon is currently designed as an autonomous **Autonomous Hacking Agent** powered by Large Language Models (LLMs).
Here is a look back at the evolutionary milestones of Decepticon.
## 2021: Purple Team AI
In the early stages, the concept originated as a **Purple Team AI**. The fundamental idea was to create a continuous, automated feedback loop between offense and defense.
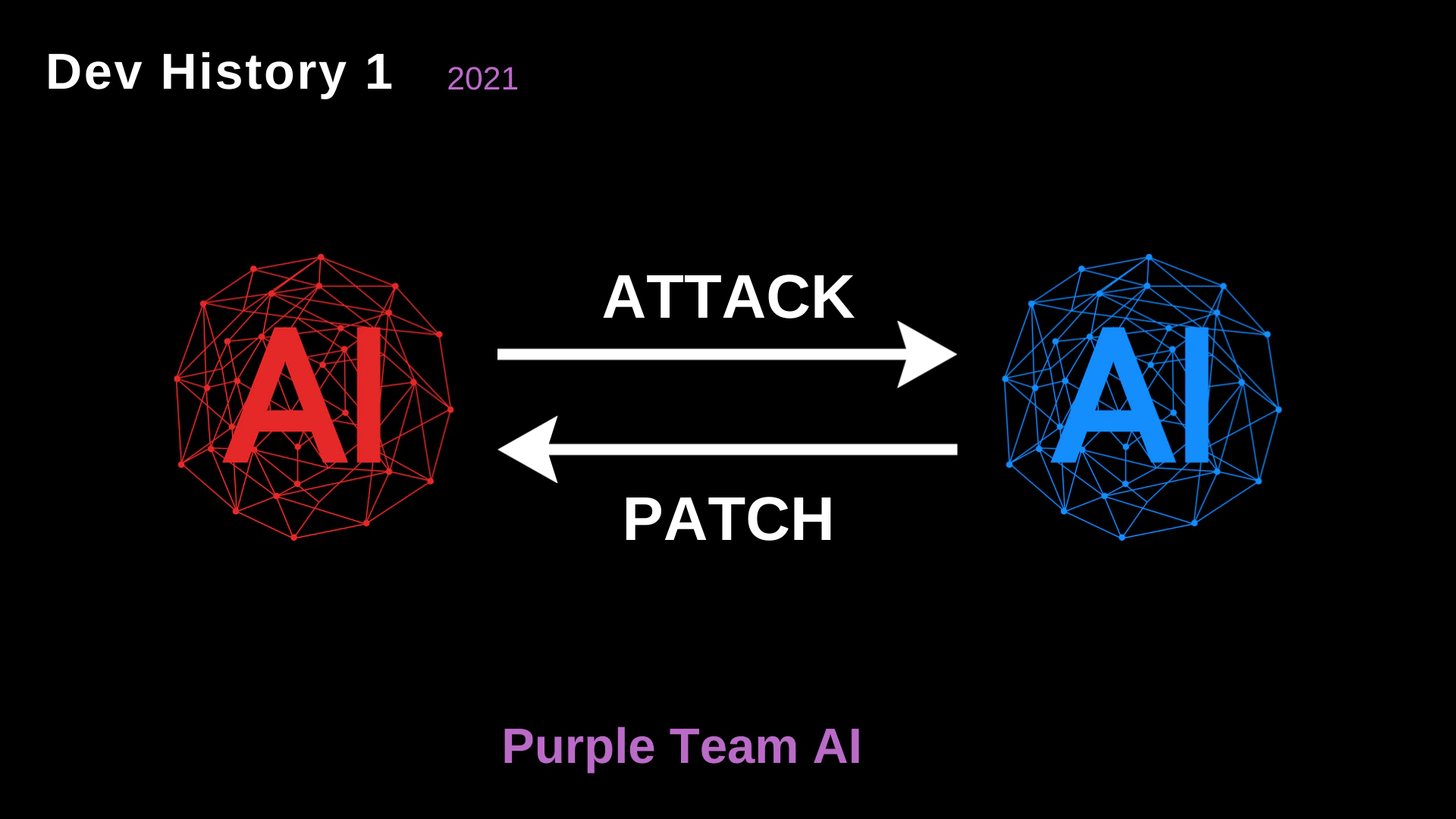 * **Red AI vs. Blue AI**: We envisioned two opposing AI models. The Red AI would launch attacks, and the Blue AI would analyze the attack vectors and issue patches.
* **The Philosophy**: Security is not static. By pitting two AIs against each other, the overarching system (the Purple Team) inherently becomes stronger over time.
## 2022: Reinforcement Learning (RL) Environment
To move beyond abstract concepts, we attempted to ground the interaction within a concrete network simulation using **Reinforcement Learning (RL)**.
* **Red AI vs. Blue AI**: We envisioned two opposing AI models. The Red AI would launch attacks, and the Blue AI would analyze the attack vectors and issue patches.
* **The Philosophy**: Security is not static. By pitting two AIs against each other, the overarching system (the Purple Team) inherently becomes stronger over time.
## 2022: Reinforcement Learning (RL) Environment
To move beyond abstract concepts, we attempted to ground the interaction within a concrete network simulation using **Reinforcement Learning (RL)**.
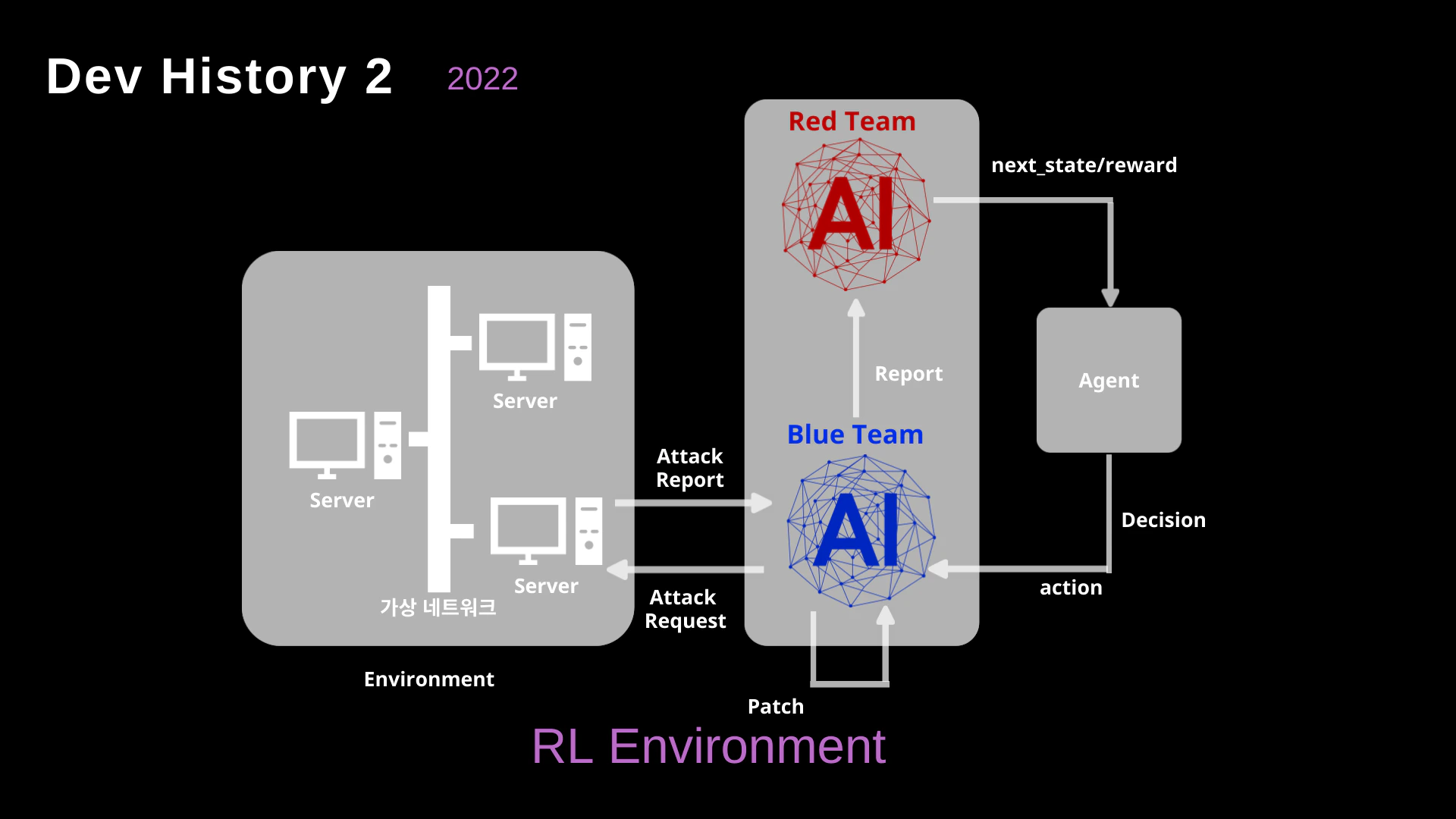 * **The Virtual Network**: We built environments containing simulated servers and networks.
* **Agent-Based Learning**: The Red Team AI would issue "Attack Requests", and the environment would return the "next\_state" or a "reward" based on the attack's success.
* **The Challenge**: While RL is powerful for games with defined rules (like Chess or Go), real-world network environments and "vibes" are infinitely complex. Designing accurate reward functions for every possible cyberattack vector proved to be a massive bottleneck.
## 2023: Generative Adversarial Networks (GANs)
Recognizing the difficulty of defining rigid RL environments, we explored the use of **Generative Adversarial Networks (GANs)** to simulate attack data.
* **The Virtual Network**: We built environments containing simulated servers and networks.
* **Agent-Based Learning**: The Red Team AI would issue "Attack Requests", and the environment would return the "next\_state" or a "reward" based on the attack's success.
* **The Challenge**: While RL is powerful for games with defined rules (like Chess or Go), real-world network environments and "vibes" are infinitely complex. Designing accurate reward functions for every possible cyberattack vector proved to be a massive bottleneck.
## 2023: Generative Adversarial Networks (GANs)
Recognizing the difficulty of defining rigid RL environments, we explored the use of **Generative Adversarial Networks (GANs)** to simulate attack data.
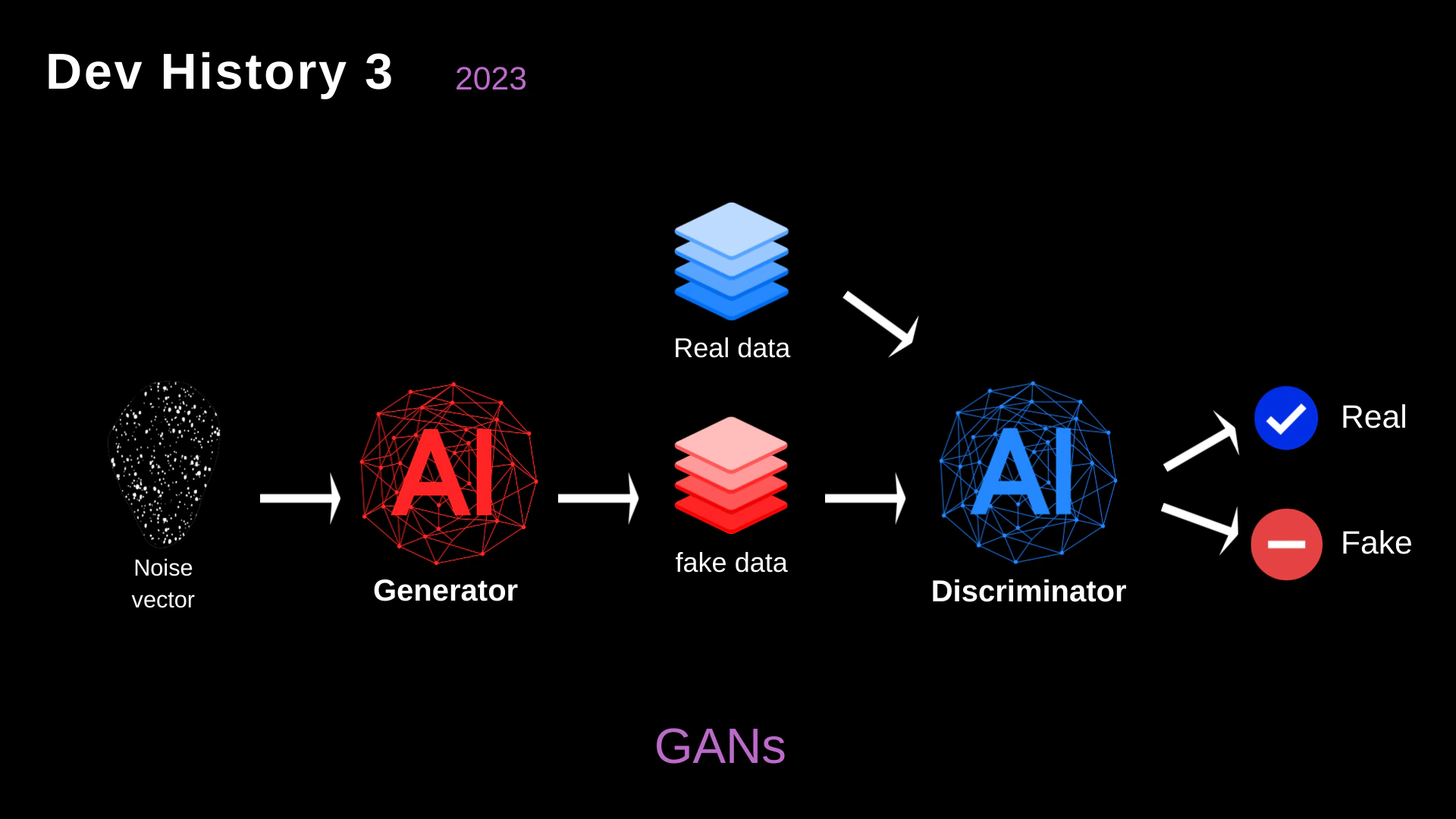 * **Generator vs. Discriminator**: In this architecture, the Generator (acting offensively) tried to create "fake data" (attack payloads) that looked like normal network traffic. The Discriminator (acting defensively) tried to distinguish between real, benign traffic and the malicious fakes.
* **The Limitation**: GANs were excellent at generating payloads that bypassed signature-based WAFs (Web Application Firewalls). However, they lacked *contextual understanding*. They couldn't perform multi-stage attacks, read a server's response, or pivot through a network dynamically.
## Present: The Autonomous Hacking Agent
Through these iterative failures and successes, we realized that true offensive capability requires more than mathematical optimization or payload generation. It requires **reasoning**.
Today, Decepticon leverages advanced LLMs to act as an autonomous agent. Instead of relying on rigid environments or statistical distributions, it reads the "vibe" of the target—understanding human context, adapting to complex defenses, and executing multi-stage Red Team operations.
* **Generator vs. Discriminator**: In this architecture, the Generator (acting offensively) tried to create "fake data" (attack payloads) that looked like normal network traffic. The Discriminator (acting defensively) tried to distinguish between real, benign traffic and the malicious fakes.
* **The Limitation**: GANs were excellent at generating payloads that bypassed signature-based WAFs (Web Application Firewalls). However, they lacked *contextual understanding*. They couldn't perform multi-stage attacks, read a server's response, or pivot through a network dynamically.
## Present: The Autonomous Hacking Agent
Through these iterative failures and successes, we realized that true offensive capability requires more than mathematical optimization or payload generation. It requires **reasoning**.
Today, Decepticon leverages advanced LLMs to act as an autonomous agent. Instead of relying on rigid environments or statistical distributions, it reads the "vibe" of the target—understanding human context, adapting to complex defenses, and executing multi-stage Red Team operations.