2021년: 퍼플팀 AI (Purple Team AI)
초기 단계에서 이 프로젝트는 **퍼플팀 AI(Purple Team AI)**라는 컨셉에서 출발했습니다. 근본적인 아이디어는 공격과 방어 사이에 지속적이고 자동화된 피드백 루프를 구축하는 것이었습니다.
- Red AI vs. Blue AI: 우리는 서로 대립하는 두 개의 AI 모델을 구상했습니다. Red AI는 공격을 수행하고, Blue AI는 그 공격 벡터를 분석하여 패치를 발행합니다.
- 핵심 철학: 보안은 정적인 상태가 아닙니다. 두 AI를 서로 경쟁시킴으로써, 이를 아우르는 전체 시스템(퍼플팀)은 시간이 지남에 따라 필연적으로 더욱 강력해진다는 철학이었습니다.
2022년: 강화학습 환경 (RL Environment)
추상적인 컨셉을 넘어 실제 네트워크 시뮬레이션 환경에 이를 적용하기 위해, 우리는 **강화학습(Reinforcement Learning, RL)**을 도입했습니다.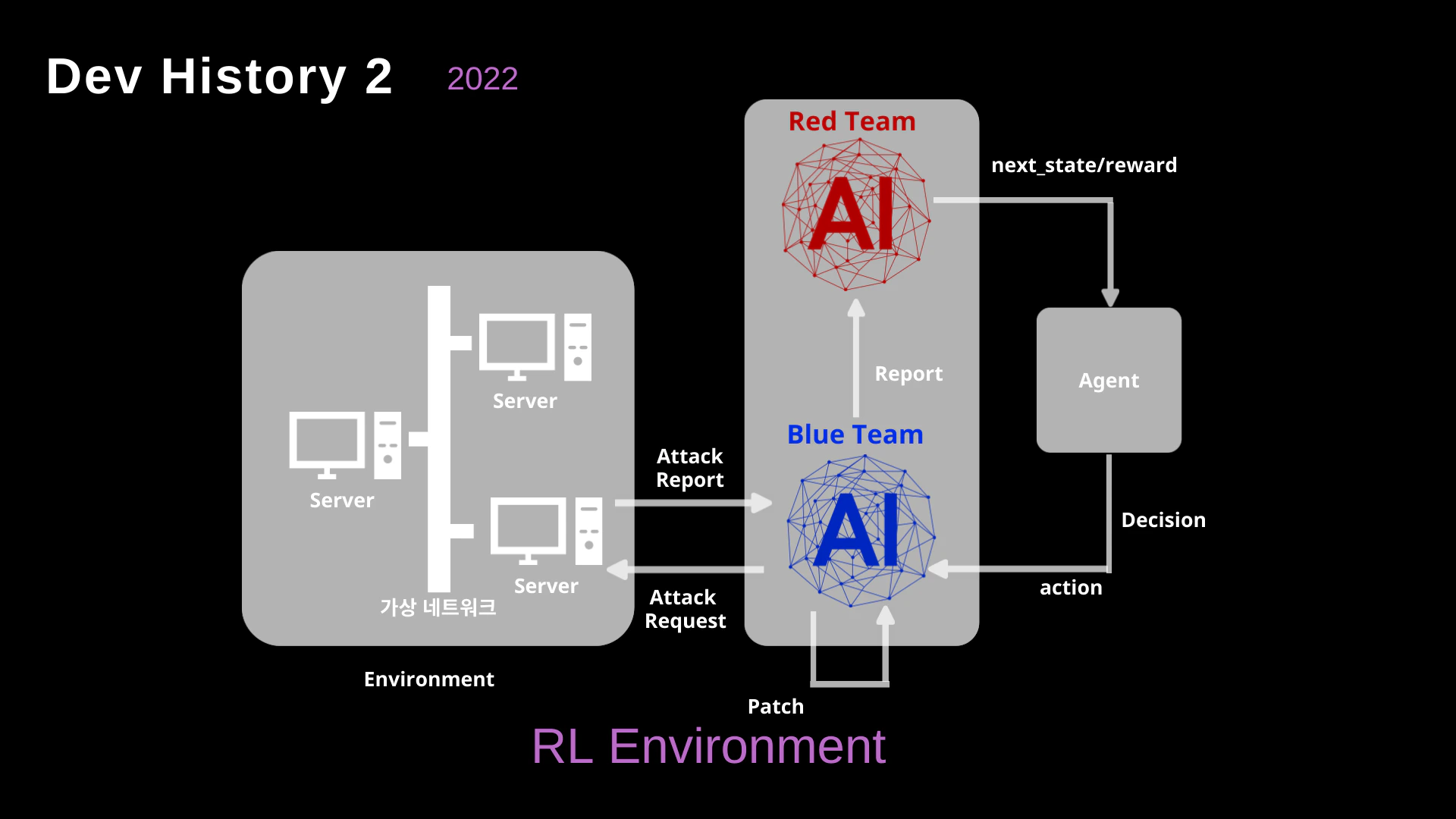
- 가상 네트워크 (Virtual Network): 시뮬레이션된 서버와 네트워크로 구성된 환경(Environment)을 구축했습니다.
- 에이전트 기반 학습 (Agent-Based Learning): 레드팀 AI(에이전트)가 “공격 요청(Attack Request)“을 보내면, 환경은 공격의 성공 여부에 따라 “초기 상태(next_state)” 혹은 “보상(Reward)“을 반환합니다.
- 한계점: 체스나 바둑처럼 규칙이 명확한 게임에서 강화학습은 강력하지만, 현실 세계의 네트워크 환경과 문맥(“Vibe”)은 무한히 복잡합니다. 현존하는 수많은 사이버 공격 벡터 각각에 대해 정확한 보상 함수(Reward function)를 설계하는 것은 엄청난 병목(Bottleneck)이었습니다.
2023년: 적대적 생성 신경망 (GANs)
강대한 RL 환경 구축의 어려움을 깨닫고, 우리는 공격 데이터를 시뮬레이션하기 위해 **적대적 생성 신경망(GANs, Generative Adversarial Networks)**의 사용을 연구했습니다.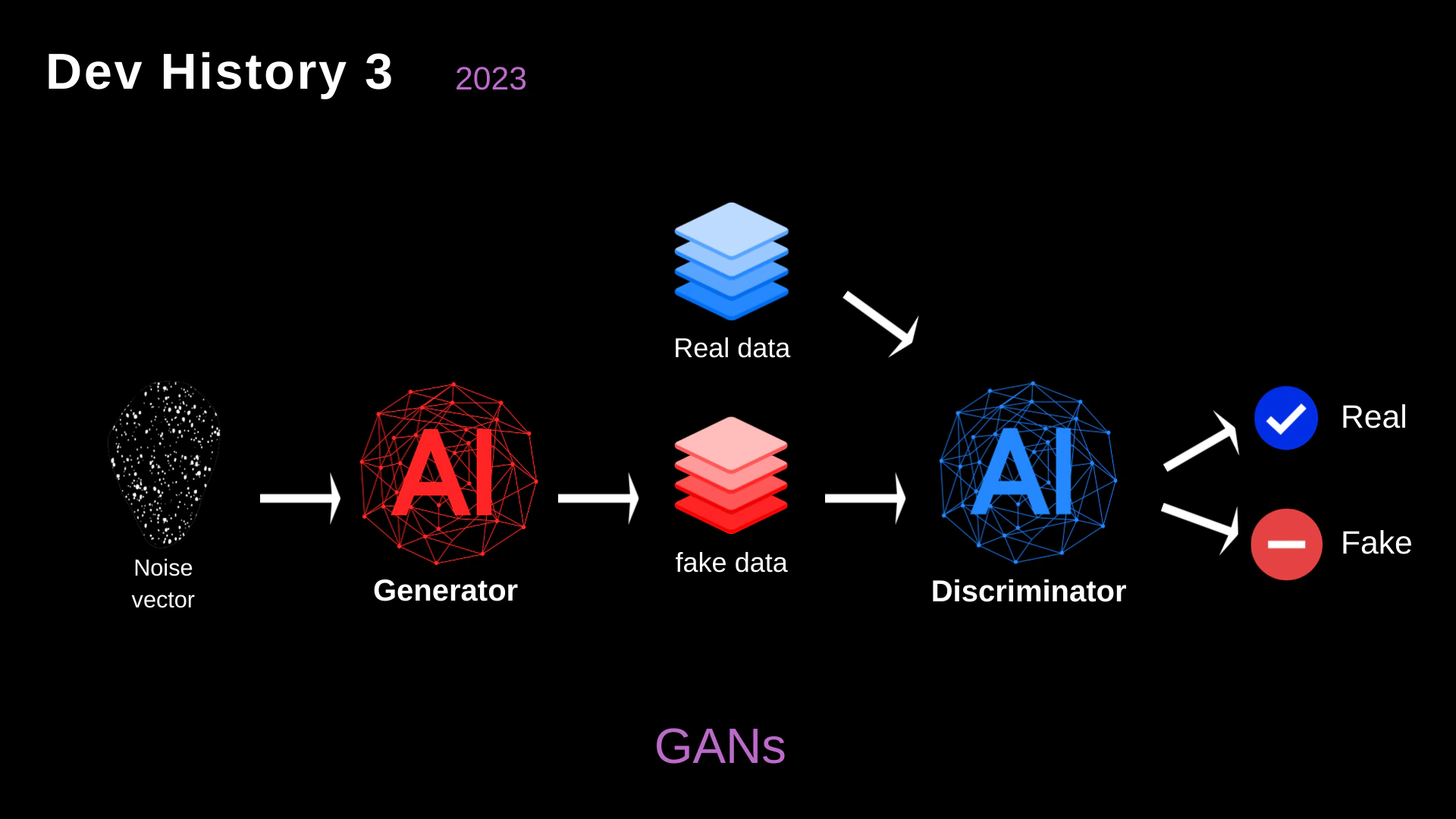
- 생성자 vs 판별자 (Generator vs. Discriminator): 이 아키텍처에서는 오펜시브 역할을 맡은 생성자(Generator)가 정상적인 네트워크 트래픽처럼 보이는 “가짜 데이터(공격 페이로드)“를 만들려고 시도합니다. 반대로 방어 역할을 맡은 판별자(Discriminator)는 실제 정상 트래픽과 악성 가짜 트래픽을 구분하려고 시도합니다.
- 한계점: GAN은 서명 기반(Signature-based)의 웹 방화벽(WAF)을 우회하는 페이로드를 생성하는 데는 탁월했습니다. 하지만 **문맥에 대한 이해(Contextual understanding)**가 결여되어 있었습니다. 여러 단계에 걸친 복잡한 공격을 수행하거나, 서버의 응답을 읽고 방향을 틀어 동적으로 내부망을 탐색(Pivoting)하는 것은 불가능했습니다.